The history of streaming processing systems


In 2004, Google's three papers([1], [2], [3]) unveiled the era of big data processing. While those systems were designed for large scale batch processing, a few years later streaming processing system received more and more attention. Unlike batch processing systems, which generally process data in days or hours, stream processing systems have shorter response times, which greatly improves the timeliness of data systems.
In this article I'll introduce the history several popular streaming processing systems, which has been widely used in industry to serve online traffic. Following diagram shows the timeline of different streaming systems.

Apache Storm and its successors
Apache storm was the first widely used distributed streaming system in internet company. It provides a low level api for user to build topology, e.g. a directed acyclic graph, which consists of spouts, bolts and streams connecting these components. In its early version, it only provides at least once or at most once guarantee, and can only do stateless processing. Storm trident is a high level data flow api to provide stateful, exactly once processing, which is built on primitives provided by low level apis.
Apache storm was quite popular, but there are several severe problems in its design when applied to large scale traffic:
Difficult to do back pressure. To achieve at least once processing, storm maintains emitted tuples in memory, and sends ack messages to spouts to remove fully processed tuples. However, it uses a timeout mechanism to do failure detection, e.g. if a tuple hasn't been acked for a while, it resends the tuple. This makes back pressure impossible since it may introduce resends in spouts.
Difficult to achieve exactly once processing. Althought trident api provides exactly one guarantee, it's based on mini batch mechanism, and difficult to use and tune in production.
Resource management. For a long time, storm community doesn't integrate with popular resource management systems such as yarn, mesos and kubenetes. Users need to maintain dedicated hosts for storm cluster, and due to storm lacks resource isolation, usually each storm job needs a separate cluster.
Baidu also developed a similar streaming processing system using c++, and most designs were inspired by storm. Apache apex was just another streaming system which had similar api and designs as storm.
Twitter heron is storm's successor in twitter after twitter acquired storm's team. It improved several things such as resource management, back pressure, etc. But it didn't change the fault tolerant mechanism used by storm.
Google Millwheel
Millwheel[4] is google's in house streaming processing engine, written in c++. Its design is much more elegant and provides several features that have profound impact on later systems:
Exactly once processing. Similar to storm, millwheel provides low level api for computing and building topology. However, it provides exactly once processing by default. It achieves this by storing states in bigtable, and using acks to acknowledge a message is successfully processed.
Decoupled compute and storage. Though it was designed 10 years ago, millwheel's design was quite cloud native. By storing its states in bigtable, it can easily scale its compute and storage independently. With this approach, it would be quite easy to handle traffic change and data skew smoothly.
Watermark. In real life events arrive to system in disorder.Without watermark, the streaming system can never know when all events arrive, and the state size of streaming processing system will grow to infinity.
Google millwheel's design can achieve record level with exactly once processing. However when ultra low latency requirement is not that critical, its throughput is lower than other systems such as apache flink.
Google dataflow unified both streaming and batch processing with some concepts inspired by millwheel, such as window, trigger, and watermark.
Apache Spark Structure Streaming
Spark structure streaming, which was named Spark Streaming before, is a streaming processing engine built on apache spark. Apache spark was originally designed for batch processing, and spark streaming runs on spark by converting streaming data into mini batches.
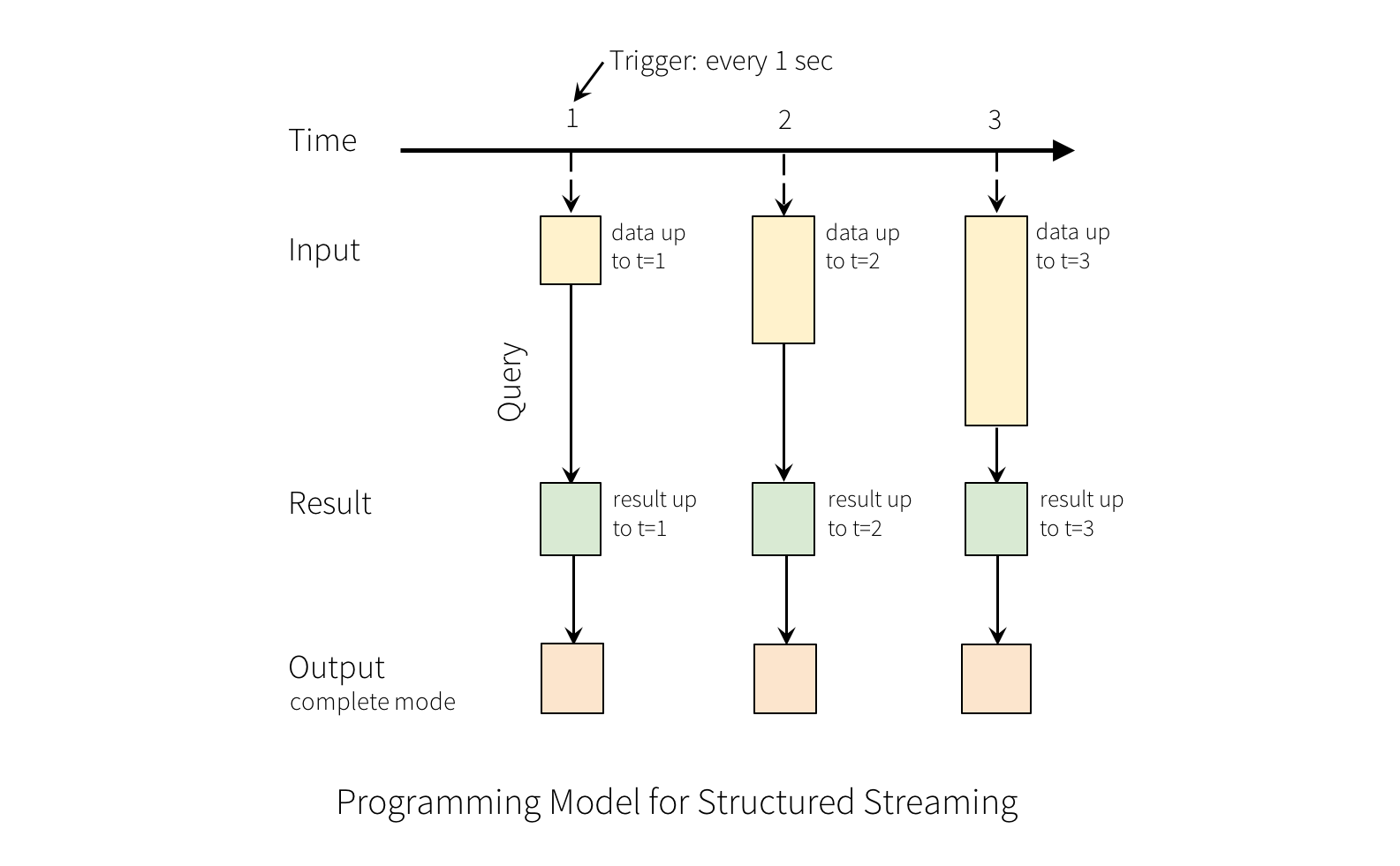
This way spark streaming can leverage all the optimization in spark engine, which is quite robust and highly optimized. But it's hard to achieve low latency in spark streaming, since the cost of scheduling and planning can't be avoided in every batch.
Apache Flink
Apache flink is currently the most popular and defacto standard of streaming processing systems. It provides exactly once, stateful streaming processing with a high-level dataflow api. Also, flink sql allows users to write a streaming application only using sql, which makes streaming applications easier to develop. There are many elegant designs in flink, but I will only talk about two of them in this article due to space limitation.
Fault Tolerant
Flink's fault-tolerant mechanism is inspired by Chandy-Lamport's async barrier snapshot algorithm. Flink will insert checkpoint barriers into record streams, which flow through the whole job graph along with records. When a checkpoint barrier is received, flink will make a snapshot of the current state and upload it to persist storage such as hdfs. When failure happens, the whole system will restore to the last successfully uploaded checkpoint.

With this algorithm, flink achieves the goal of high throughput and low latency. Compared with google millwheel, flink has higher throughput. But the disadvantage is that it can achieve record level exactly-once processing. It's impossible to do a snapshot for each record, even with incremental checkpointing.
Local State
Flink supports pluggable state backends, and it keeps the state of each partition along with the corresponding operator on the same host. This design can improve performance since it avoids remote access, also it simplified flink's architecture so that it doesn't depend on a high-performance kv storage, but just hdfs.
The drawback of local state is that it coupled compute with storage, which makes resource allocation less efficient in cloud environment. What's more, it makes auto-scaling less smooth since when an operator is moved around, it requires reloading all of its states into local disk.
Conclusion
Streaming processing is becoming more and more important nowadays. In this article, I talked about the essentials of several popular streaming processing systems, and also the pros and cons of their design. I believe streaming processing will keep improving and evolving in cloud.
References
https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41378.pdf